I just completed work on the digital transformation, design, development, and delivery of a cloud native data solution for one of the biggest professional sports organizations in north America.
In this post, I want to share some thoughts on the selected architecture and why we settled on it
This Architecture was chosen to meet the following requirements gathered through a very involved and collaborative process with the customer:
- It should be open and flexible. Allowing for the ability to build and deliver solutions using the best services and cloud native products available.
- The architecture should enable integration between products/tools/services to allow for efficient running, scalability, and support for a variety of data formats.
- It should enable insights by simplifying the ability to build analytics dashboards and operational reports.
- It should unify data, analytics, and ML workloads.
The architecture is shown in the following screenshot:
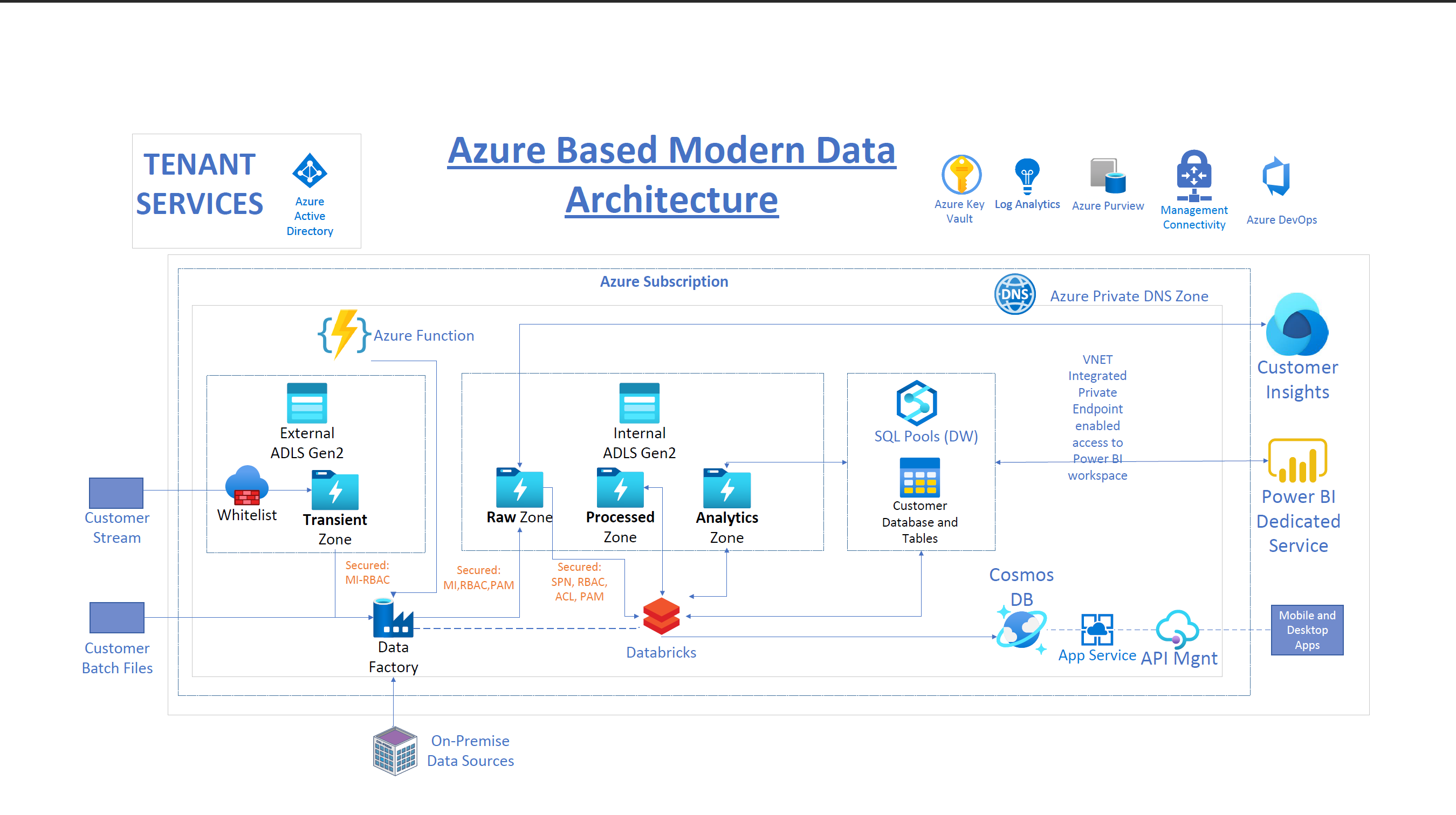
This solution meets these requirements by integrating:
Azure Databricks:
Built on the open-source Apache Spark and Delta Lake. Databricks is capable of efficiently handling both batch and near real-time data workloads as required in this project.
A combination of Spark Structured streaming with the trigger once option and Databricks Autoloader enabled us to develop for near real-time processing scenarios, while reusing the same codebase to meet batch processing requirements when and where necessary. In addition, Databricks Autoloader enables incremental file processing, without having to separately set up corresponding infrastructure for storage queues and event grid.
The exciting Delta Lake technology that implements the Lakehouse usage pattern enables a number of exciting features that have facilitated the implementation of schema evolution, merge, updates and inserts to data lake files. The Python implementation of these features allowed us to take advantage of existing skillsets and quickly meet business requirements without writing overly long and complex pipeline code.
Use of the same code base helped efficiently manage the ingestion and processing of both workloads. Data source files are organized into RAW, PROCESSED and ANALYTICS zones. Databricks reads from the RAW zone, does the data cleansing and transformation, then outputs the resulting Dataframe to the processed zone.
Further enrichments are performed on the processed zone files and output to the Analytics zone. This flow matches the medallion design of bronze, silver and gold zones.
Azure Data Factory and Azure Data Lake Gen 2:
We provisioned Azure Data Factory within its managed VNET. It’s also configured with private endpoints to enable secure, private integration with both instances of Azure Data Lake. Two data lakes were set up to isolate traffic and access between the external facing lake for 3rd party access and the inside facing data lake. The ADF private endpoints ensure that traffic between these two instances is isolated.
IP Address whitelisting was set up on the outside-facing data lake firewall to control 3rd party access. The inside data lake is accessible via private endpoints and restricted VNETs.
In addition, we provisioned an Azure virtual machine to host the ADF self-hosted runtime. This was used for secure, non-public access to Azure Databricks. Azure Databricks does not support private endpoints currently. Details of this setup will be addressed in a future post.
We provisioned Data Lake containers into RAW, PROCESSED and ANALYTICS zones, with appropriate RBACs and ACLs configured for clearly defined service principals where necessary for security isolation and access control.
The data flow is that ADF writes to the RAW zone in the internal data lake and Databricks/Apache Spark reads from this zone, does the data cleansing and transformation, then outputs the resulting Dataframe to the processed zone and the analytics zone based on the aggregation requirements of the business.
Azure Synapse Analytics:
We primarily used the data warehousing sub resource SQL dedicated pool for structured data storage. Transformed, structured and other profile data from Azure Databricks is written to Synapse dedicated SQL pool, and Azure Cosmos DB as needed.
The workspace was deployed within its managed VNET. Secure access via Synapse Studio is ensured via Synapse private link hub and private endpoint. Other Synapse sub resources, dev, serverless SQL and dedicated SQL pool were configured with private endpoints terminating in the same restricted VNET as the Azure Databricks deployment, but in separate subnets, enabling secure Dataframe writes from Azure Databricks to Synapse dedicated SQL pool.
Azure Monitor (Log Analytics):
I developed custom PySpark and native Python functions to capture Spark Structured streaming metrics to be published to Azure Log Analytics. This will enable Kusto queries, dashboards, and alerts for monitoring pipeline thresholds.
The solution consists of two Python functions that extract Spark Structured streaming metrics from the Streaming query, then writes them to Azure monitor Log Analytics via a REST API endpoint. I packaged these functions into a Python wheel file to make them easily reusable and deployable to a Databricks cluster.
Power BI Workspace:
Power BI is connected to the Data Lake, Azure Synapse Analytics and Azure Databricks dbfs via VNET integration and private endpoints.
The network design was based on a hub and spoke model with VNET peering and the services in this solution use Azure Active Directory (Azure AD) to authenticate users.
In future posts, as bandwidth permits, I hope to share code samples to demonstrate the automated deployment and configuration of some of the services included in this architecture.
