Overview.
Ingesting, storing and processing millions of telemetry data from a plethora of remote IoT devices and Sensors has become common place. One of the primary Cloud services used to process streaming telemetry events at scale is Azure Event Hub.
Most documented implementations of Azure Databricks Ingestion from Azure Event Hub Data are based on Scala.
So, in this post, I outline how to use PySpark on Azure Databricks to ingest and process telemetry data from an Azure Event Hub instance configured without Event Capture.
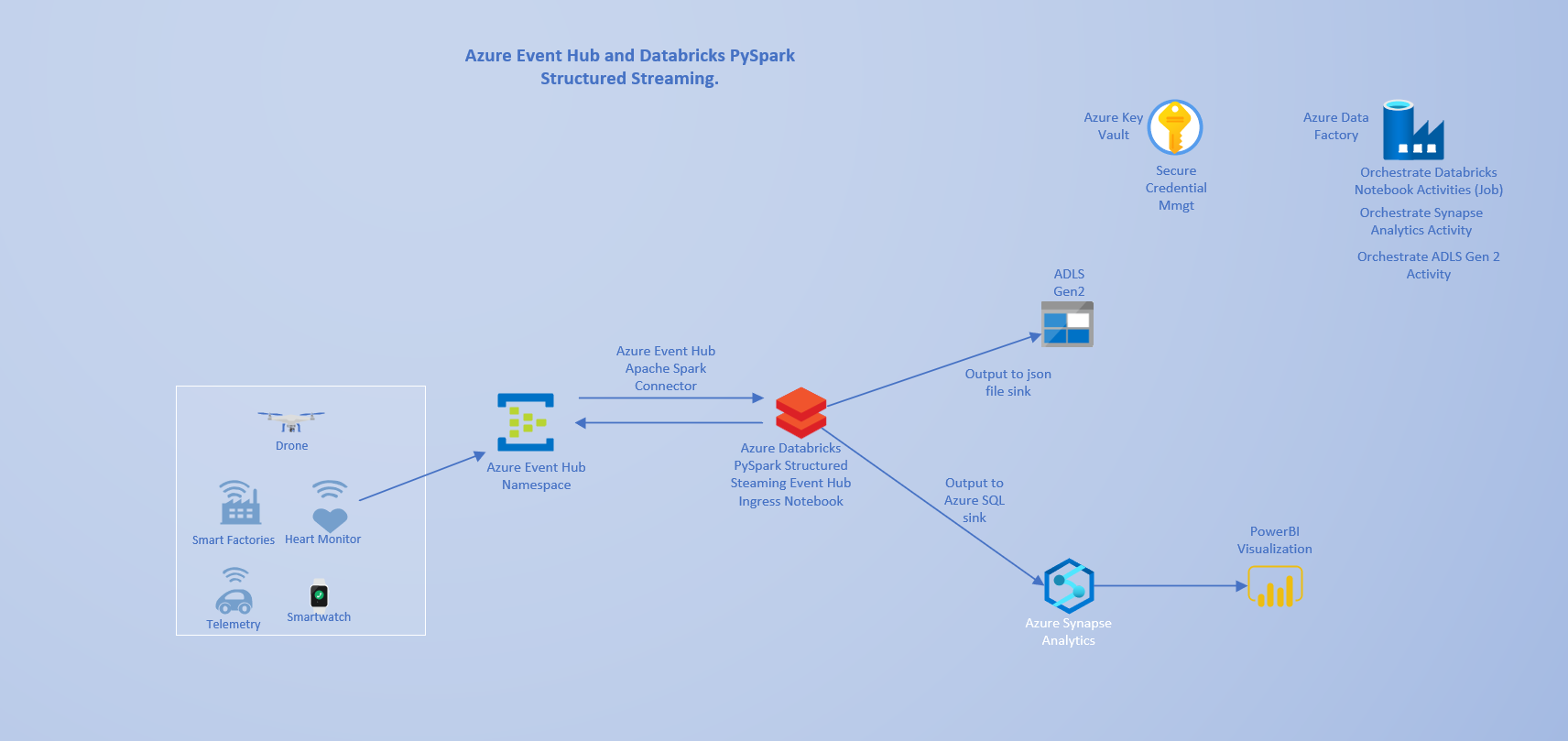
My workflow and Architecture design for this use case include IoT sensors as the data source, Azure Event Hub, Azure Databricks, ADLS Gen 2 and Azure Synapse Analytics as output sink targets and Power BI for Data Visualization. Orchestration pipelines are built and managed with Azure Data Factory and secrets/credentials are stored in Azure Key Vault.
Requirements.
- An Azure Event Hub service must be provisioned. I will not go into the details of provisioning an Azure Event Hub resource in this post. The steps are well documented on the Azure document site.
- Create an Azure Databricks workspace and provision a Databricks Cluster. To match the artifact id requirements of the Apache Spark Event hub connector: azure-eventhubs-spark_2.12, I have provisioned a Databricks cluster with the 7.5 runtime.
- To enable Databricks to successfully ingest and transform Event Hub messages, install the Azure Event Hubs Connector for Apache Spark from the Maven repository in the provisioned Databricks cluster. For this post, I have installed the version 2.3.18 of the connector, using the following maven coordinate: “com.microsoft.azure:azure-eventhubs-spark_2.12:2.3.18“. This library is the most current package at the time of this writing.
Architecture.
Configuration and Notebook Code Prep.
- Create an Event Hub instance in the previously created Azure Event Hub namespace.
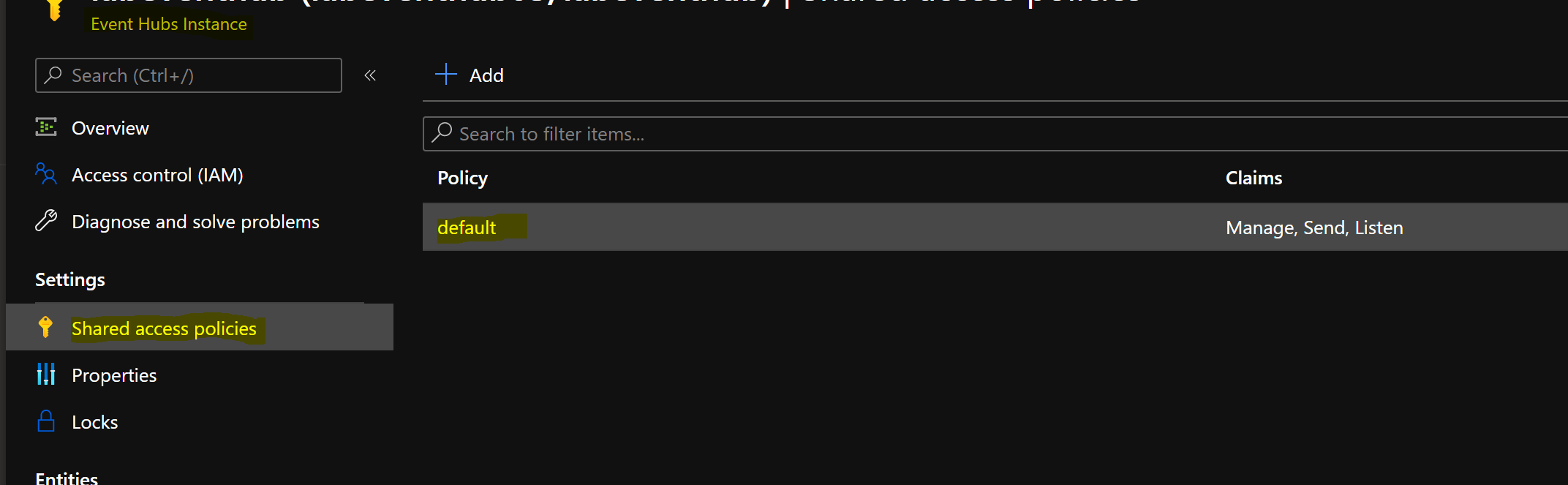
- Create a new Shared Access Policy in the Event Hub instance. Copy the connection string generated with the new policy. Note that this connection string has an “EntityPath” component , unlike the RootManageSharedAccessKey connectionstring for the Event Hub namespace.
- Install the Azure Event Hubs Connector for Apache Spark referenced in the Overview section.
To authenticate and connect to the Azure Event Hub instance from Azure Databricks, the Event Hub instance connection string is required. The connection string must contain the EntityPath property. Please note that the Event Hub instance is not the same as the Event Hub namespace. The Event Hub namespace is the scoping container for the Event hub instance.
The connection string located in the RootManageSharedAccessKey associated with the Event Hub namespace does not contain the EntityPath property, it is important to make this distinction because this property is required to successfully connect to the Hub from Azure Databricks.
If the EntityPath property is not present, the connectionStringBuilder object can be used to make a connectionString that contains the required components.
The connection string (with the EntityPath) can be retrieved from the Azure Portal as shown in the following screen shot:
I recommend storing the Event Hub instance connection string in Azure Key Vault as a secret and retrieving the secret/credential using the Databricks Utility as displayed in the following code snippet:
connectionString = dbutils.secrets.get("myscope", key="eventhubconnstr")
An Event Hub configuration dictionary object that contains the connection string property must be defined. All configurations relating to Event Hubs are configured in this dictionary object. In addition, the configuration dictionary object requires that the connection string property be encrypted.
# Initialize event hub config dictionary with connectionString
ehConf = {}
ehConf['eventhubs.connectionString'] = connectionString
# Add consumer group to the ehConf dictionary
ehConf['eventhubs.consumerGroup'] = "$Default"
# Encrypt ehConf connectionString property
ehConf['eventhubs.connectionString'] = sc._jvm.org.apache.spark.eventhubs.EventHubsUtils.encrypt(connectionString)
Use the PySpark Streaming API to Read Events from the Event Hub.
Now that we have successfully configured the Event Hub dictionary object. We will proceed to use the Structured Streaming readStream API to read the events from the Event Hub as shown in the following code snippet.
# Read events from the Event Hub
df = spark.readStream.format("eventhubs").options(**ehConf).load()
# Visualize the Dataframe in realtime
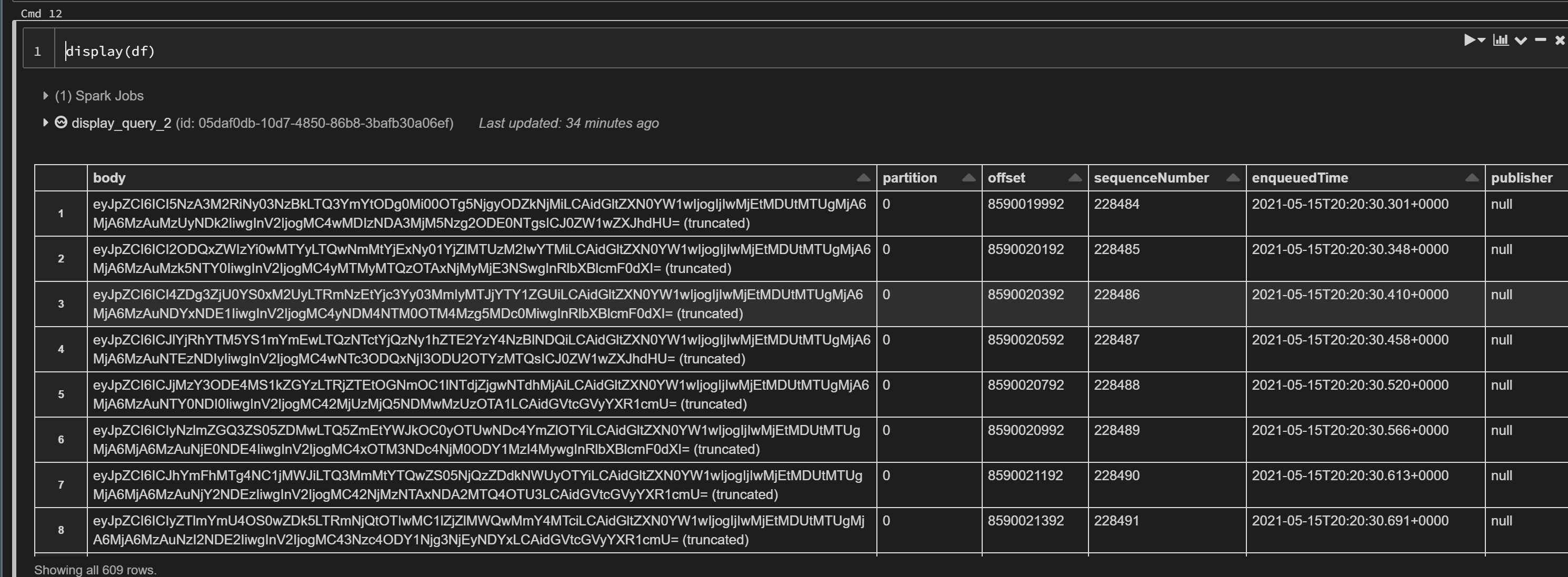
display(df)
Using the Databricks display function, we can visualize the structured streaming Dataframe in real time and observe that the actual message events are contained within the “Body” field as binary data. Some transformation will be required to convert and extract this data.
The goal is to transform the DataFrame in order to extract the actual events from the “Body” column. To achieve this, we define a schema object that matches the fields/columns in the actual events data, map the schema to the DataFrame query and convert the Body field to a string column type as demonstrated in the following snippet:
# Write stream into defined sink
from pyspark.sql.types import *
import pyspark.sql.functions as F
events_schema = StructType([
StructField("id", StringType(), True),
StructField("timestamp", StringType(), True),
StructField("uv", StringType(), True),
StructField("temperature", StringType(), True),
StructField("humidity", StringType(), True)])
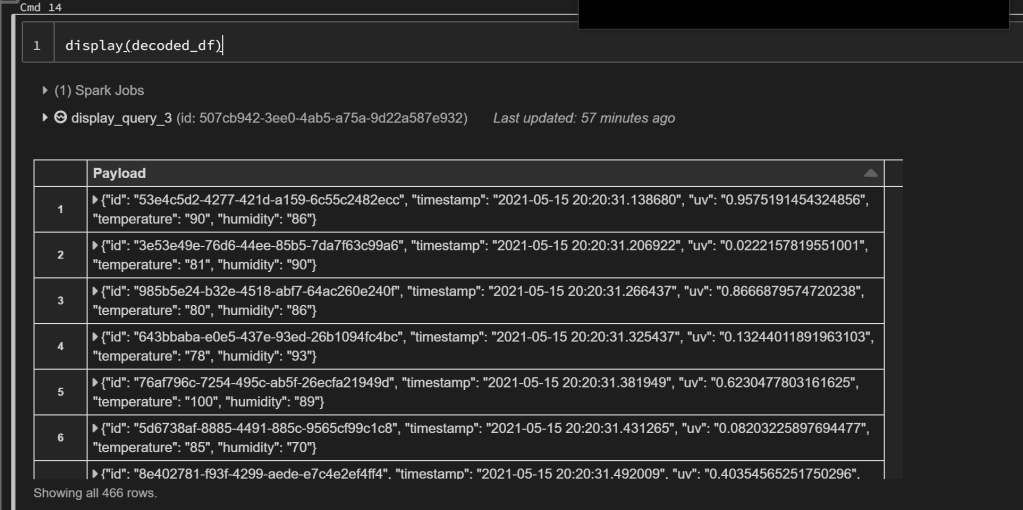
decoded_df = df.select(F.from_json(F.col("body").cast("string"), events_schema).alias("Payload"))
# Visualize the transformed df
display(decoded_df)
Further transformation is needed on the DataFrame to flatten the JSON properties into separate columns and write the events to a Data Lake container in JSON file format.
# Flatten the JSON properties into separate columns
df_events = decoded_df.select(decoded_df.Payload.id, decoded_df.Payload.timestamp, decoded_df.Payload.uv, decoded_df.Payload.temperature, decoded_df.Payload.humidity)
# Write stream to Data Lake in JSON file formats
df_out = df_events.writeStream\
.format("json")\
.outputMode("append")\
.option("checkpointLocation", "abfss://checkpointcontainer@adlstore.dfs.core.windows.net/checkpointapievents")\
.start("abfss://api-eventhub@store05.dfs.core.windows.net/writedata")
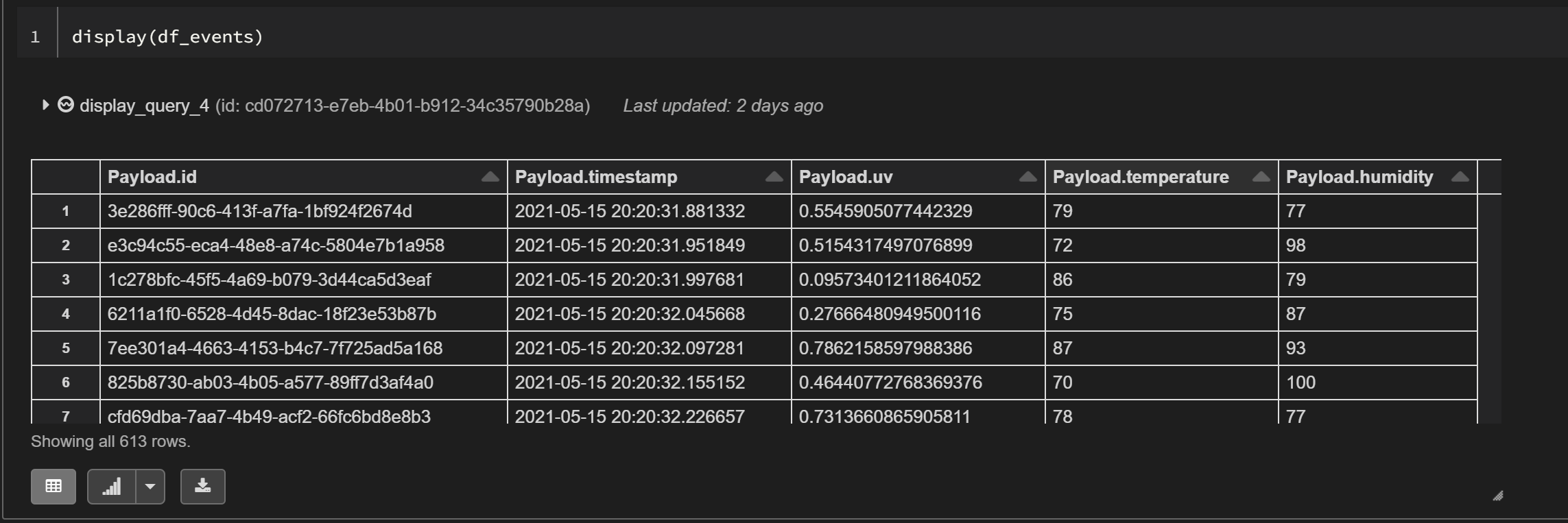
Specific business needs will require writing the DataFrame to a Data Lake container and to a table in Azure Synapse Analytics.
The downstream data is read by Power BI and reports can be created to gain business insights into the telemetry stream.
So far in this post, we have outlined manual and interactive steps for reading and transforming data from Azure Event Hub in a Databricks notebook.
To productionize and operationalize these steps we will have to 1. Automate cluster creation via the Databricks Jobs REST API. 2. Automate the installation of the Maven Package. 3. Perhaps execute the Job on a schedule or to run continuously (this might require configuring Data Lake Event Capture on the Event Hub).
To achieve the above-mentioned requirements, we will need to integrate with Azure Data Factory, a cloud based orchestration and scheduling service.
As time permits, I hope to follow up with a post that demonstrates how to build a Data Factory orchestration pipeline productionizes these interactive steps. We could use a Data Factory notebook activity or trigger a custom Python function that makes REST API calls to the Databricks Jobs API.
The complete PySpark notebook is available here.

One response to “Ingest Azure Event Hub Telemetry Data with Apache PySpark Structured Streaming on Databricks.”
Great Post! Thanks!