Overview.
At the time of this writing, there doesn’t seem to be built-in support for writing PySpark Structured Streaming query metrics from Azure Databricks to Azure Log Analytics. After some research, I found a work around that enables capturing the Streaming query metrics as a Python dictionary object from within a notebook session and publishing those metrics to Azure Log Analytics using the Log Analytics Data Collector REST API.
A PySpark streaming query processes data in micro-batches. Information on the completed process is captured via a Streaming Query object. The lastProgress() property of this object returns specific metrics that provide details of the executed query and processed data. These are returned as a Python Dictionary. Some of the information attributes returned are:
id
Unique identifier tied to a checkpoint location. This stays the same throughout the lifetime of a query (i.e., across restarts).
runId
Unique identifier for the current (re)started instance of the query. This changes with every restart.
numInputRows
Number of input rows that were processed in the last micro-batch.
inputRowsPerSecond
Current rate at which input rows are being generated at the source (average over the last micro-batch duration).
processedRowsPerSecond
Current rate at which rows are being processed and written out by the sink (average over the last micro-batch duration). If this rate is consistently lower than the input rate, then the query is unable to process data as fast as it is being generated by the source. This is a key indicator of the health of the query.
sources and sink
Provides source/sink-specific details of the data processed in the last batch.
Solution.
My solution consists of two Python functions that extract these metrics and others from the Streaming query, then writes them to Azure monitor Log Analytics via a REST API. I built these functions into a Python wheel package to make them easily reusable and deployable to a cluster.
The first of the two functions builds the Authorization signature required to authenticate the HTTP Data Collector API POST request using the primary or secondary workspace key. More information explaining the details of the Python 3 function can be found here.
Following is my adapted version of the source code :
import json
import requests
import datetime
import hashlib
import hmac
import base64
"""
Custom Functions to implement publishing PySpark Streaming metrics to Azure Log Analytics.
"""
#Build the API signature
def build_signature(customer_id, shared_key, date, content_length, method, content_type, resource):
x_headers = 'x-ms-date:' + date
string_to_hash = method + "\n" + str(content_length) + "\n" + content_type + "\n" + x_headers + "\n" + resource
bytes_to_hash = str.encode(string_to_hash,'utf-8')
decoded_key = base64.b64decode(shared_key)
encoded_hash = (base64.b64encode(hmac.new(decoded_key, bytes_to_hash, digestmod=hashlib.sha256).digest())).decode()
authorization = "SharedKey {}:{}".format(customer_id,encoded_hash)
return authorization
#Build and send a request to the POST API
def post_data(customer_id, shared_key, body, log_type):
method = 'POST'
content_type = 'application/json'
resource = '/api/logs'
rfc1123date = datetime.datetime.utcnow().strftime('%a, %d %b %Y %H:%M:%S GMT')
content_length = len(body)
signature = build_signature(customer_id, shared_key, rfc1123date, content_length, method, content_type, resource)
uri = 'https://' + customer_id + '.ods.opinsights.azure.com' + resource + '?api-version=2016-04-01'
headers = {
'content-type': content_type,
'Authorization': signature,
'Log-Type': log_type,
'x-ms-date': rfc1123date
}
response = requests.post(uri,data=body, headers=headers)
if (response.status_code >= 200 and response.status_code <= 299):
print ('Accepted')
else:
print ("Response code: {}".format(response.status_code))
To use the functions in a Databricks cluster, I built the file into a Python wheel package/library for reusability and easy installation on the clusters. The setup.py file used to build the package is as follows:
"""A setuptools based setup module. See: Setup file to build custom PySpark Streaming Logging package. """ # Always prefer setuptools over distutils import setuptools import pathlib here = pathlib.Path(__file__).parent.resolve() # Get the long description from the README file long_description = (here / 'README.md').read_text(encoding='utf-8') # Arguments marked as "Required" below must be included for upload to PyPI. # Fields marked as "Optional" may be commented out. # Run the following command to build the wheel file package: python.exe .\setup.py sdist bdist_wheel setuptools.setup( name="pyspark_streaming_logging", version="0.0.1", author="myusername", author_email="username@mail.com", description="My custom packages for publishing PySpark Streaming Metrics to Azure Log Analytics", long_description=long_description, long_description_content_type="text/markdown", url="", packages=setuptools.find_packages(), classifiers=[ "Programming Language :: Python :: 3", "License :: OSI Approved :: MIT License", "Operating System :: OS Independent", ], python_requires='>=3.6', # This field lists other packages that your project depends on to run. # Any package you put here will be installed by pip when your project is # installed, so they must be valid existing projects. # # For an analysis of "install_requires" vs pip's requirements files see: # https://packaging.python.org/en/latest/requirements.html install_requires=['multisig-hmac'] # Optional )
The following command generates the wheel package in the dist folder:
PS C:\sourcecode\wheel_packages_repo> python.exe .\setup.py sdist bdist_wheel
Deploy the Library into a Databricks Cluster:
The custom wheel package/library can be deployed into a Databricks cluster using a cluster init script. The script is defined as part of the cluster creation configuration and can be executed via Databricks cluster create REST API. Following is a snippet of the cluster configuration JSON file:
{
"num_workers": null,
"autoscale": {
"min_workers": 2,
"max_workers": 3
},
"cluster_name": "log_analytics_cluster",
"spark_version": "7.3.x-scala2.12",
"spark_conf": {
"spark.databricks.passthrough.enabled": "true"
},
"node_type_id": "Standard_DS3_v2",
"ssh_public_keys": [],
"custom_tags": {},
"cluster_log_conf": {
"dbfs": {
"destination": "dbfs:/cluster-logs"
}
},
"spark_env_vars": {
"PYSPARK_PYTHON": "/databricks/python3/bin/python3"
},
"autotermination_minutes": 30,
"init_scripts": [
{
"dbfs": {
"destination": "dbfs:/databricks/custom_libs/cluster_init_whl.sh"
}
}
]
}
After successful installation of the library, it can be imported into the python notebook like any other python library. The following screenshot and code snippet show how to use the library in a Spark (Python) notebook:
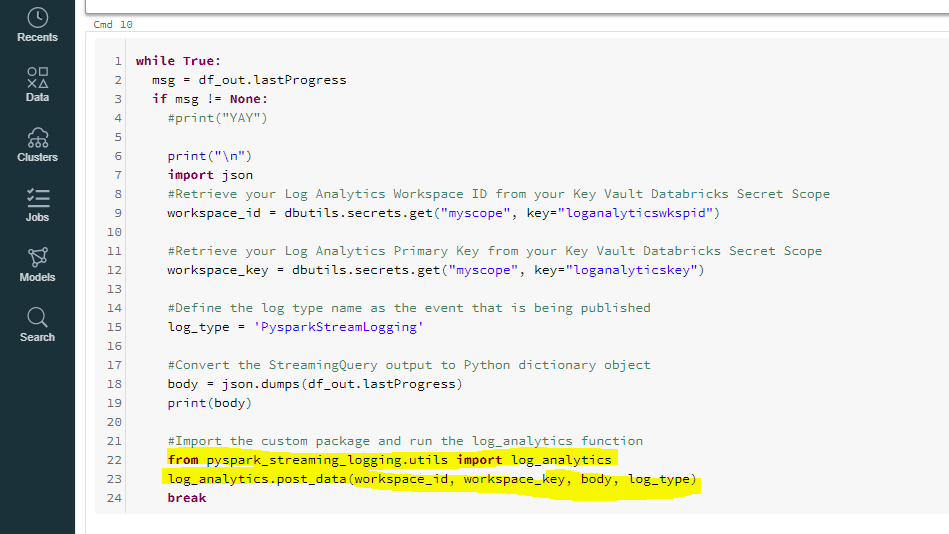
while True:
msg = df_out.lastProgress
if msg != None:
#print("YAY")
print("\n")
import json
#Retrieve your Log Analytics Workspace ID from your Key Vault Databricks Secret Scope
workspace_id = dbutils.secrets.get("myscope", key="loganalyticswkspid")
#Retrieve your Log Analytics Primary Key from your Key Vault Databricks Secret Scope
workspace_key = dbutils.secrets.get("myscope", key="loganalyticskey")
#Define the log type name as the event that is being published
log_type = 'PysparkStreamLogging'
#Convert the StreamingQuery output to Python dictionary object
body = json.dumps(df_out.lastProgress)
print(body)
#Import the custom package and run the log_analytics function
from pyspark_streaming_logging.utils import log_analytics
log_analytics.post_data(workspace_id, workspace_key, body, log_type)
break
Write to Azure Log Analytics.
To test the Log Analytics integration with my Spark Application logs, I setup a Databricks Job based on the notebook PySpark application and library dependency. After executing the Job, the application log results were written to the specified log analytics workspace. Following is a screenshot of the Log Analytics workspace with the Kusto query and a subset of the results:
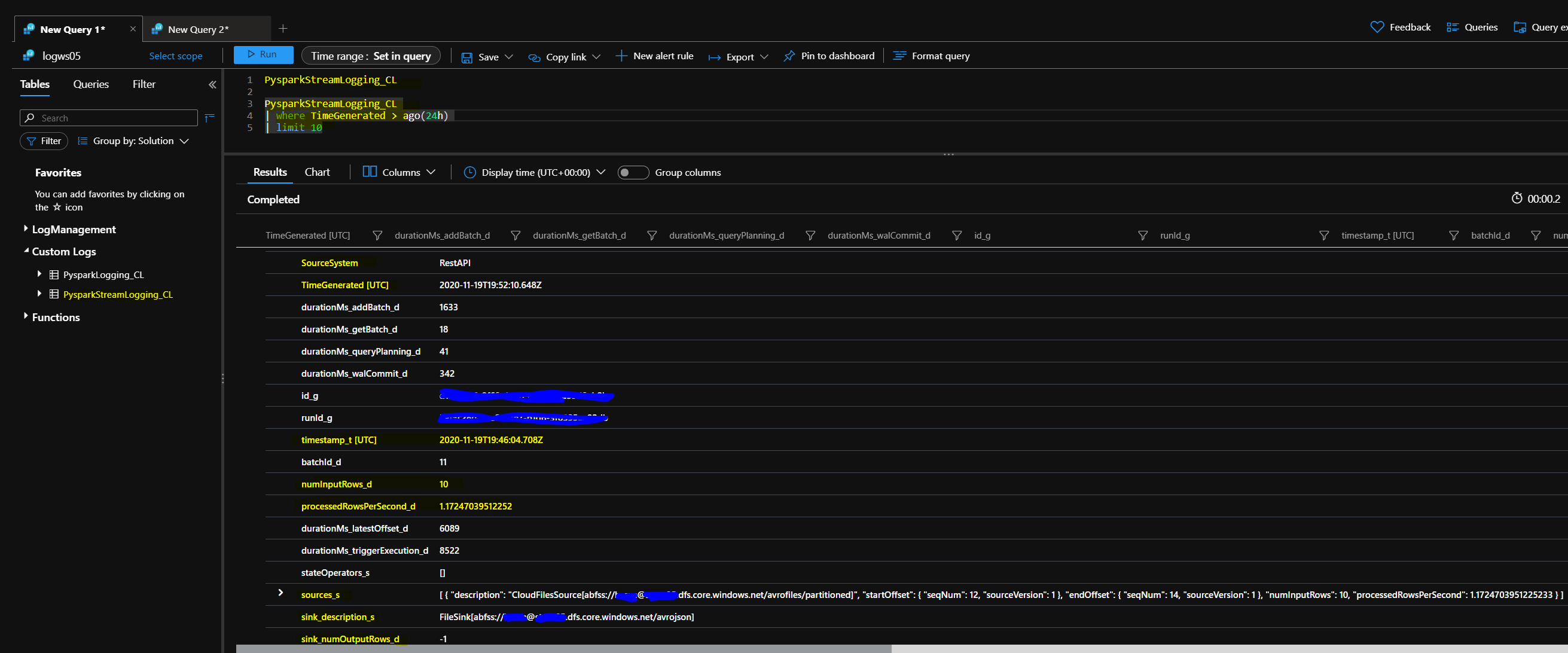
Summary.
As I mentioned earlier, this is a custom work around that gets the job done with regards to publishing a subset of Databricks Pyspark application logs. I have come across a separate custom Scala/Java based solution that captures a lot more metrics. I hope to share my work adapting that solution soon. Hopefully, a more holistic and Databricks native solution is currently in the works and will be available soon.

One response to “Publish PySpark Streaming Query Metrics to Azure Log Analytics using the Data Collector REST API.”
[…] Publish PySpark Streaming Query Metrics to Azure Log Analytics using the Data Collector REST API. via jbernec […]