-
Shipping a Multi-Agent Application on Azure: What Production Actually Looks Like
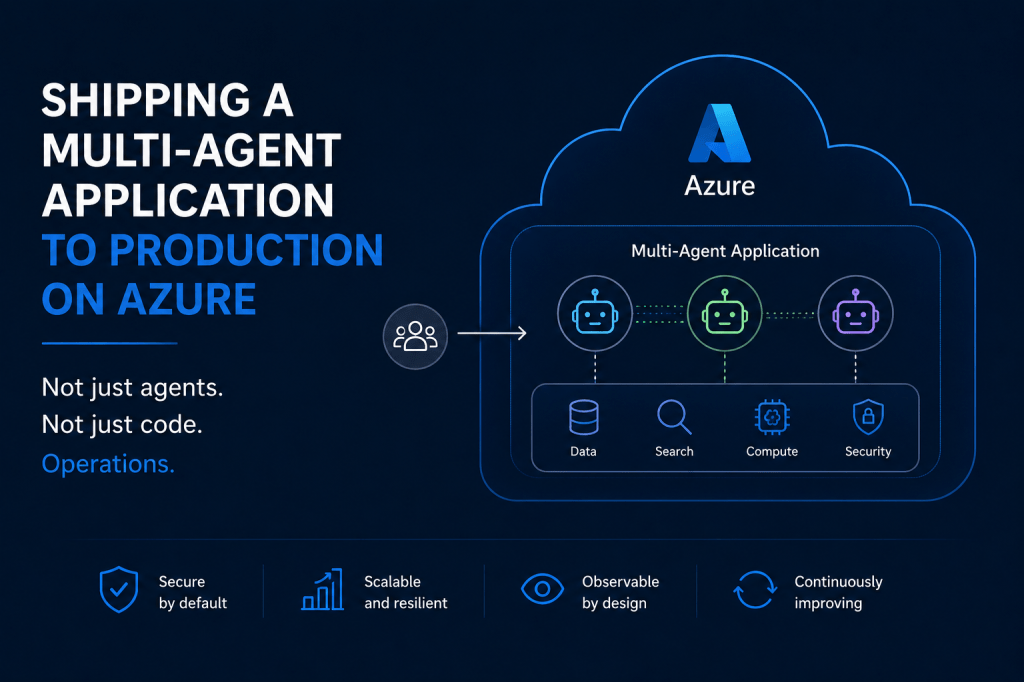
Users see a chat interface. They type a question, get an answer, maybe a chart. Simple. Behind that interface, a small fleet of agents queries data, runs spend-response curves, optimizes channel allocations, and renders plots. The work is analytical, not transactional: nothing they do writes back to source systems or changes external state. Underneath all…
-
Twenty Years Beyond the Veil: Mother.

It has been twenty years since you stepped beyond this world,not lost, only hiddenfrom the reach of our eyes. Yet you remain. Not as memory fading with time, but as living truth within us, eternal values carved into our souls, quietly shaping every choice, every becoming. Your voice still echoes,not in sound alonebut in the…
-
The Sandbox Shift: Why Kernel-Level Containment, + Local Models, Is Redefining Autonomous AI for the Rest of Us

Something fundamental is changing in how autonomous AI systems are built, deployed, and secured. And it’s not about bigger models, better prompts, or cheaper API calls. It’s about locally hosted models, SLMs and where the trust boundary lives. For the past three years, the dominant approach to making AI agents “safe” has been to tell the…
-
Vibe Coding Meets Spec Engineering – What Building With AI Agents Really Looks Like

One is great for exploration, the other for accumulation. Here’s what happens when you use both. Vibe coding is having a moment. Andrej Karpathy coined the term, and suddenly everyone’s doing it, you open a chat, describe what you want in plain English, let the AI generate code, and just go with the vibes. Accept all,…
-
Securing Multi-Agent AI with Entra ID On-Behalf-Of: Per-User RBAC in LangGraph.
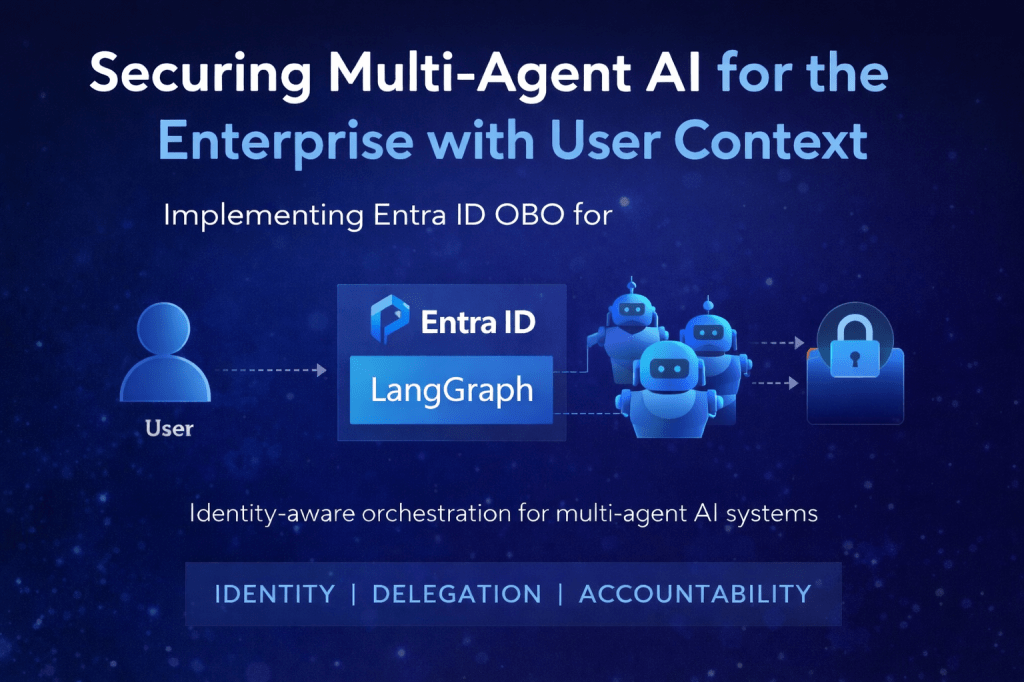
This is the first of two posts. This one focuses on the technical aspects; the next will address the CXOs perspective, providing a comprehensive unified point of view. Introduction When building AI-powered applications for the enterprise, a common challenge emerges: how do you maintain user identity and access controls when an AI agent queries backend…
-
The Tectonic Shift: AI Agents and the Future of Work.

The future of work is changing rapidly with the rise of AI Agents in the enterprise. From user-friendly, no-code platforms like Copilot Studio that empower citizen developers, to complex agentic AI-driven pipelines orchestrating multiple agents on the backend, AI is transforming how business applications and processes are designed, deployed, and scaled across every industry vertical.…
-
Modernizing Enterprise IT & Knowledge Support with Azure-Native Multiagent AI and LangGraph.

Industry: Energy Location: North America Executive Summary: AI-Driven Multi-Agent Knowledge and IT Support Solution for an Energy Industry Firm A North American energy company sought to modernize its legacy knowledge and IT support chatbot, which was underperforming across key metrics. The existing system, built on static rules and scripts, delivered slow and often inaccurate responses,…
-
Exploring AI Agent-Driven Auto Insurance Claims RAG Pipeline.

Introduction: In this post, I explore a recent experiment aimed at creating a RAG pipeline tailored for the insurance industry, specifically for handling automobile insurance claims, with the goal of potentially reducing processing times. I also showcase the implementation of Autogen AI Agents to enhance search retrieval through agent interaction and function calls on sample…
-
Enhancing Document Extraction with Azure AI Document Intelligence and LangChain for RAG Workflows.

Overview. The broadening of conventional data engineering pipelines and applications to include document extraction and preprocessing for unstructured PDFs, audio, and video files is becoming more prevalent. This shift is propelled by the increasing demand for advanced generative AI applications in businesses, adhering to the RAG (Retrievable Augmented Generation) model. In this post, I will…
-
Designing and Implementing a Modern Data Architecture on Azure Cloud.
I just completed work on the digital transformation, design, development, and delivery of a cloud native data solution for one of the biggest professional sports organizations in north America. In this post, I want to share some thoughts on the selected architecture and why we settled on it This Architecture was chosen to meet the…
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
