In this post, I will attempt to capture the steps taken to load data from Azure Databricks deployed with VNET Injection (Network Isolation) into an instance of Azure Synapse DataWarehouse deployed within a custom VNET and configured with a private endpoint and private DNS.
Deploying these services, including Azure Data Lake Storage Gen 2 within a private endpoint and custom VNET is great because it creates a very secure Azure environment that enables limiting access to them.
But the drawback is that the security design adds extra layers of configuration in order to enable integration between Azure Databricks and Azure Synapse, then allow Synapse to import and export data from a staging directory in Azure Data Lake Gen 2 using Polybase and COPY statements. PolyBase and the COPY statements are commonly used to load data into Azure Synapse Analytics from Azure Storage accounts for high throughput data ingestion.
Quick Overview on how the connection works:
Access from Databricks PySpark application to Azure Synapse can be facilitated using the Azure Synapse Spark connector. The connector uses ADLS Gen 2, and the COPY statement in Azure Synapse to transfer large volumes of data efficiently between a Databricks cluster and an Azure Synapse instance.
Both the Databricks cluster and the Azure Synapse instance access a common ADLS Gen 2 container to exchange data between these two systems. In Databricks, Apache Spark applications read data from and write data to the ADLS Gen 2 container using the Synapse connector. On the Azure Synapse side, data loading and unloading operations performed by PolyBase are triggered by the Azure Synapse connector through JDBC. In Databricks Runtime 7.0 and above, COPY is used by default to load data into Azure Synapse by the Azure Synapse connector through JDBC because it provides better performance.
Implementation.
Step 1: Configure Access from Databricks to ADLS Gen 2 for Dataframe APIs.
a. The first step in setting up access between Databricks and Azure Synapse Analytics, is to configure OAuth 2.0 with a Service Principal for direct access to ADLS Gen2. The container that serves as the permanent source location for the data to be ingested by Azure Databricks must be set with RWX ACL permissions for the Service Principal (using the SPN object id). This can be achieved using Azure PowerShell or Azure Storage explorer.
Get the SPN object id:
Get-AzADServicePrincipal -ApplicationId dekf7221-2179-4111-9805-d5121e27uhn2 | fl Id
Id : 4037f752-9538-46e6-b550-7f2e5b9e8n83
Configure the OAuth2.0 account credentials in the Databricks notebook session:
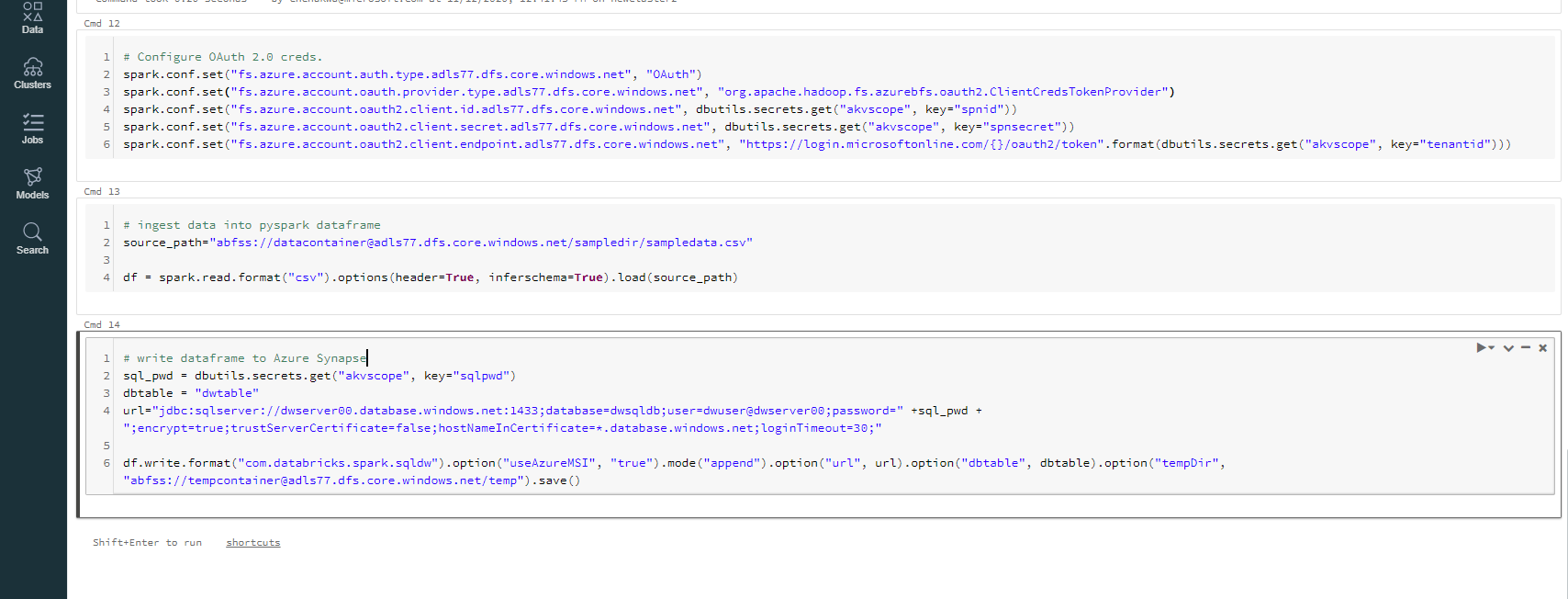
# Configure OAuth 2.0 creds.
spark.conf.set("fs.azure.account.auth.type.adls77.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.adls77.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.adls77.dfs.core.windows.net", dbutils.secrets.get("akvscope", key="spnid"))
spark.conf.set("fs.azure.account.oauth2.client.secret.adls77.dfs.core.windows.net", dbutils.secrets.get("akvscope", key="spnsecret"))
spark.conf.set("fs.azure.account.oauth2.client.endpoint.adls77.dfs.core.windows.net", "https://login.microsoftonline.com/{}/oauth2/token".format(dbutils.secrets.get("akvscope", key="tenantid")))
b. The same SPN also needs to be granted RWX ACLs on the temp/intermediate container to be used as a temporary staging location for loading/writing data to Azure Synapse Analytics.
Step 2: Use Azure PowerShell to register the Azure Synapse server with Azure AD and generate an identity for the server.
Set-AzSqlServer -ResourceGroupName rganalytics -ServerName dwserver00 -AssignIdentity
Step 3: Assign RBAC and ACL permissions to the Azure Synapse Analytics server’s managed identity:
a. Assign Storage Blob Data Contributor Azure role to the Azure Synapse Analytics server’s managed identity generated in Step 2 above, on the ADLS Gen 2 storage account. This can be achieved using Azure portal, navigating to the IAM (Identity Access Management) menu of the storage account. It can also be done using Powershell.
b. In addition, the temp/intermediate container in the ADLS Gen 2 storage account, that acts as an intermediary to store bulk data when writing to Azure Synapse, must be set with RWX ACL permission granted to the Azure Synapse Analytics server Managed Identity . This can also be done using PowerShell or Azure Storage Explorer. For more details, please reference the following article.
Step 4: Using SSMS (SQL Server Management Studio), login to the Synapse DW to configure credentials.
a. Run the following sql query to create a database scoped cred with Managed Service Identity that references the generated identity from Step 2:
CREATE DATABASE SCOPED CREDENTIAL msi_cred WITH IDENTITY = 'Managed Service Identity';
b. A master key should be created. In my case I had already created a master key earlier. The following query creates a master key in the DW:
CREATE MASTER KEY
Azure Data Warehouse does not require a password to be specified for the Master Key. If you make use of a password, take record of the password and store it in Azure Key vault.
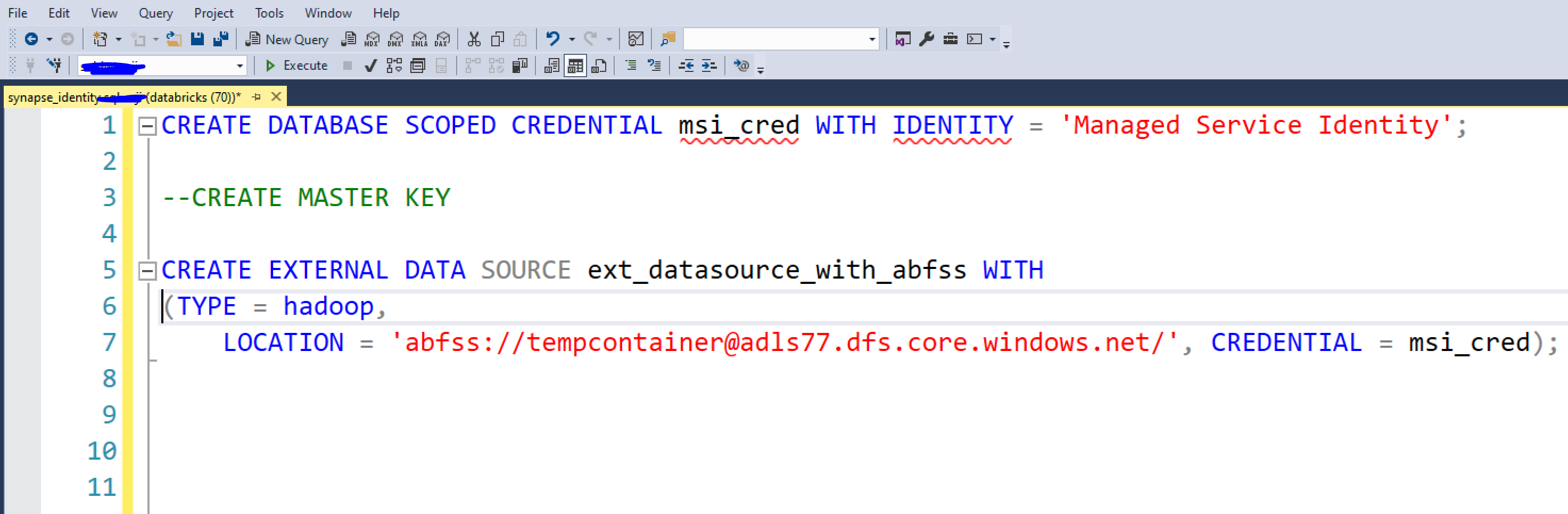
c. Run the next sql query to create an external datasource to the ADLS Gen 2 intermediate container:
CREATE EXTERNAL DATA SOURCE ext_datasource_with_abfss WITH (TYPE = hadoop, LOCATION = ‘abfss://tempcontainer@adls77.dfs.core.windows.net/’, CREDENTIAL = msi_cred);
Step 5: Read data from the ADLS Gen 2 datasource location into a Spark Dataframe.
source_path="abfss://datacontainer@adls77.dfs.core.windows.net/sampledir/sampledata.csv"
df = spark.read.format("csv").options(header=True, inferschema=True).load(source_path)
Step 6: Build the Synapse DW Server connection string and write to the Azure Synapse DW.
I have configured Azure Synapse instance with a Managed Service Identity credential. For this scenario, I must set useAzureMSI to true in my Spark Dataframe write configuration option. Based on this config, the Synapse connector will specify “IDENTITY = ‘Managed Service Identity’” for the database scoped credential and no SECRET.
sql_pwd = dbutils.secrets.get("akvscope", key="sqlpwd")
dbtable = "dwtable"
url="jdbc:sqlserver://dwserver00.database.windows.net:1433;database=dwsqldb;user=dwuser@dwserver00;password=" +sql_pwd + ";encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
df.write.format("com.databricks.spark.sqldw").option("useAzureMSI", "true").mode("append").option("url", url).option("dbtable", dbtable).option("tempDir", "abfss://tempcontainer@adls77.dfs.core.windows.net/temp").save()
The following screenshot shows the notebook code:
Summary.
As stated earlier, these services have been deployed within a custom VNET with private endpoints and private DNS. The ABFSS uri schema is a secure schema which encrypts all communication between the storage account and Azure Data Warehouse.
The Managed Service Identity allows you to create a more secure credential which is bound to the Logical Server and therefore no longer requires user details, secrets or storage keys to be shared for credentials to be created.
The Storage account security is streamlined and we now grant RBAC permissions to the Managed Service Identity for the Logical Server. In addition, ACL permissions are granted to the Managed Service Identity for the logical server on the intermediate (temp) container to allow Databricks read from and write staging data.

2 responses to “Write Data from Azure Databricks to Azure Dedicated SQL Pool(formerly SQL DW) using ADLS Gen 2.”
Thank you sooooooooo much for this post. This post solved my connectivity issue while no other help, helped.
You’re welcome 🙂