Use Case.
In this post, I will share my experience evaluating an Azure Databricks feature that hugely simplified a batch-based Data ingestion and processing ETL pipeline. Implementing an ETL pipeline to incrementally process only new files as they land in a Data Lake in near real time (periodically, every few minutes/hours) can be complicated. Since the pipeline needs to account for notifications, message queueing, proper tracking and fault tolerance to mention a few requirements. Manually designing and building out these services to work properly can be complex.
My initial architecture implementation involved using Azure Data Factory event-based trigger or tumbling window trigger to track the raw files, based on new blob (file) creation or last modified time attribute, then initiate a copy operation of the new files to a staging container.
The staging files become the source for an Azure Databricks notebook to read into an Apache Spark Dataframe, run specified transformations and output to the defined sink. A Delete activity is then used to clean up the processed files from the staging container.
This works, but it has a few drawbacks. Two of the key ones for me being:
1. The changed files copy operation could take hours depending on the number and size of the raw files. This will increase the end-to-end latency of the pipeline.
2. No easy or clear way to log/track the copied files’ processing to help with retries during a failure.
The ideal solution in my view, should include the following:
1. Enable the processing of incremental files at the source (Data Lake).
2. Eliminate the time consuming and resource intensive copy operation.
3. Maintain reliable fault tolerance.
4. Reduce overall end-to-end pipeline latency.
Enter Databricks Autoloader.
Proposed Solution.
To address the above drawbacks, I decided on Azure Databricks Autoloader and the Apache Spark Streaming API. Autoloader is an Apache Spark feature that enables the incremental processing and transformation of new files as they arrive in the Data Lake. It’s an exciting new feature that automatically provisions and configures the backend Event Grid and Azure Queue services it requires to work efficiently.
Autoloader uses a new Structured Streaming source called cloudFiles. As one of it’s configuration options, it accepts a an input source directory in the Data Lake and automatically processes new files as they land, with the option of also processing existing files in that directory. You can read more about the Autoloader feature here and here. But for the rest of this post, I will talk about my implementation of the feature.
Implement Autoloader.
Modifying my existing Architecture for Autoloader was not really complicated. I had to rewrite the data ingestion Spark code to use the Spark Structured Streaming API instead of the Structured API. My architecture looks like this:
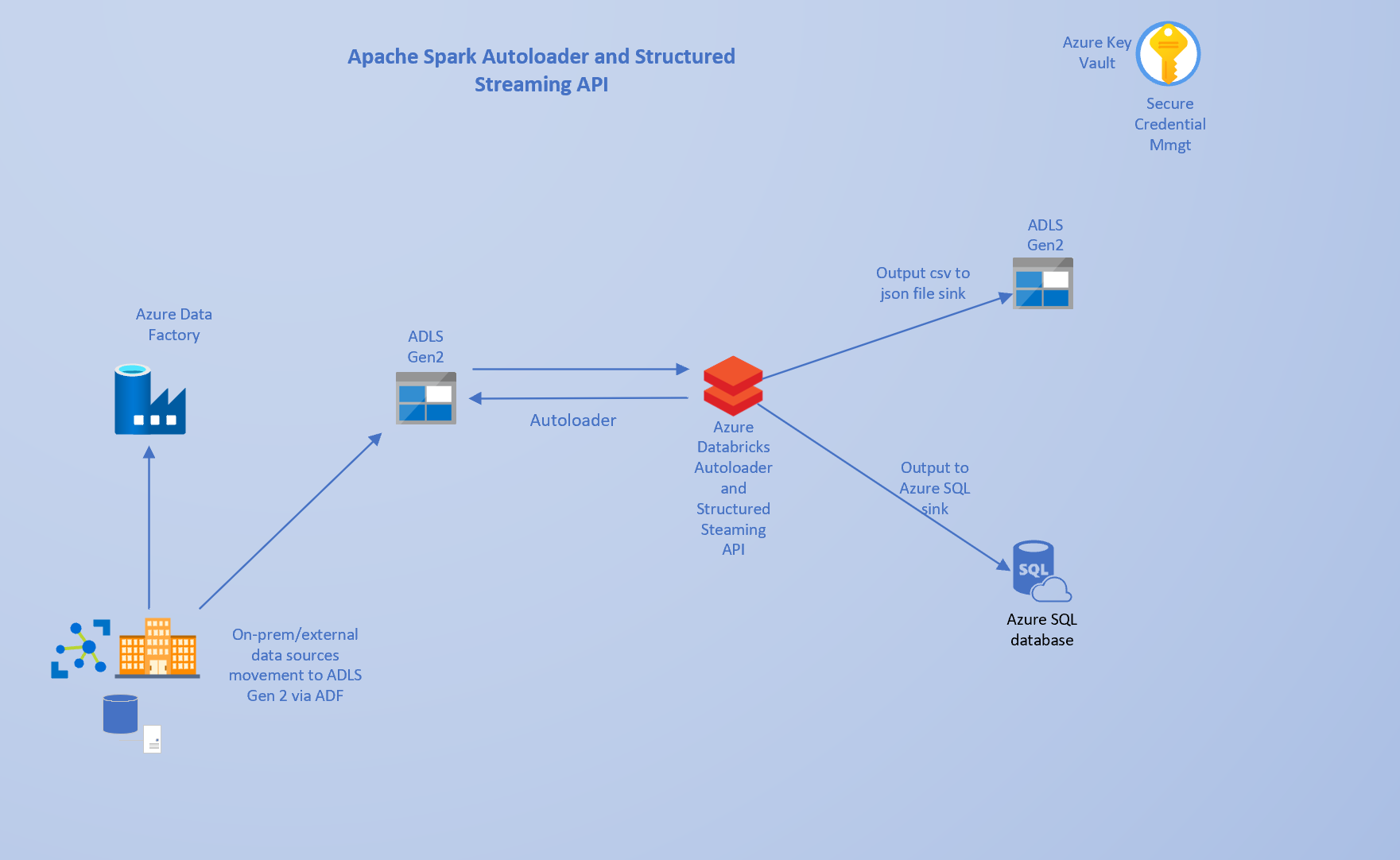
The entire implementation was accomplished within a single Databricks Notebook. In the first notebook cell show below, I configured the Spark session to access the Azure Data Lake Gen 2 Storage via direct access using a Service Principal and OAuth 2.0.
<br> # Import required modules<br> from pyspark.sql import functions as f<br> from datetime import datetime<br> from pyspark.sql.types import StringType<br>
<br>
# Configure SPN direct access to ADLS Gen 2<br>
spark.conf.set("fs.azure.account.auth.type.dstore.dfs.core.windows.net", "OAuth")<br>
spark.conf.set("fs.azure.account.oauth.provider.type.dstore.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")<br>
spark.conf.set("fs.azure.account.oauth2.client.id.dstore.dfs.core.windows.net", dbutils.secrets.get("myscope", key="clientid"))<br>
spark.conf.set("fs.azure.account.oauth2.client.secret.dstore.dfs.core.windows.net", dbutils.secrets.get("myscope", key="clientsecret"))<br>
spark.conf.set("fs.azure.account.oauth2.client.endpoint.dstore.dfs.core.windows.net", "https://login.microsoftonline.com/{}/oauth2/token".format(dbutils.secrets.get("myscope", key="tenantid")))<br>
Read a single source csv file into a Spark Dataframe to retrieve current schema. Then use the schema to configure the Autoloader readStream code segment.
<br>
df = spark.read.format("csv").option("inferSchema", True).option("header", True).load("abfss://rawcontainer@dstore.dfs.core.windows.net/mockcsv/file1.csv")</p>
<p>dataset_schema = df.schema</p>
<p>
As mentioned earlier, Autoloader provides a new cloudFiles source with configuration options to enable the incremental processing of new files as they arrive in the Data Lake. The following configuration options need to be configured for Autoloader to work properly:
1. “cloudFiles.clientId”: Provision a Service Principal with Contributor access to the ADLS Gen 2 storage account resource group to enable Autoloader create an Event Grid service and Azure Queue storage service in the background. Autoloader creates these services automatically without any manual input.
2. “cloudFiles.includeExistingFiles”: This option determines whether to include existing files in the input path in the streaming processing versus only processing new files arrived after setting up the notifications. This option is respected only when you start a stream for the first time. Changing its value at stream restart won’t take any effect.
3. “cloudFiles.format”: This option specifies the input dataset file format.
4. “cloudFiles.useNotifications”: This option specifies whether to use file notification mode to determine when there are new files. If false, use directory listing mode.
The next code segment demonstrates reading the source files into a Spark Dataframe using the Streaming API, with the cloudFiles options:
<br>
connection_string = dbutils.secrets.get("myscope", key="storageconnstr")</p>
<p>df_stream_in = spark.readStream.format("cloudFiles").option("cloudFiles.useNotifications", True).option("cloudFiles.format", "csv")\<br>
.option("cloudFiles.connectionString", connection_string)\<br>
.option("cloudFiles.resourceGroup", "rganalytics")\<br>
.option("cloudFiles.subscriptionId", dbutils.secrets.get("myscope", key="subid"))\<br>
.option("cloudFiles.tenantId", dbutils.secrets.get("myscope", key="tenantid"))\<br>
.option("cloudFiles.clientId", dbutils.secrets.get("myscope", key="clientid"))\<br>
.option("cloudFiles.clientSecret", dbutils.secrets.get("myscope", key="clientsecret"))\<br>
.option("cloudFiles.region", "eastus")\<br>
.schema(dataset_schema)\<br>
.option("cloudFiles.includeExistingFiles", True).load("abfss://rawcontainer@dstore.dfs.core.windows.net/mockcsv/")<br>
Define a simple custom user defined function to implement a transformation on the input stream dataframes. For this demo, I used a simple function that adds a column with constant values to the dataframe. Also, define a second function that will be used to write the streaming dataframe to an Azure SQL Database output sink.
<br>
# Custom function<br>
def time_col():<br>
pass<br>
return datetime.now().strftime("%d/%m/%Y %H:%M:%S")</p>
<p># UDF Function<br>
time_col_udf = spark.udf.register("time_col_sql_udf", time_col, StringType())</p>
<p># Custom function to output streaming dataframe to Azure SQL<br>
def output_sqldb(batch_df, batch_id):<br>
# Set Azure SQL DB Properties and Conn String<br>
sql_pwd = dbutils.secrets.get(scope = "myscope", key = "sqlpwd")<br>
dbtable = "staging"<br>
jdbc_url = "jdbc:sqlserver://sqlserver09.database.windows.net:1433;database=demodb;user=sqladmin@sqlserver09;password="+ sql_pwd +";encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"<br>
# write the pyspark dataframe df_spark_test to Azure SQL DB<br>
batch_df.write.format("jdbc").mode("append").option("url", jdbc_url).option("dbtable", dbtable).save()</p>
<p># Add new constant column using the UDF above to the streaming Dataframe<br>
df_transform = df_stream_in.withColumn("time_col", f.lit(time_col_udf()))<br>
Use the writeStream Streaming API method to output the transformed Dataframe into a file output sink as JSON files and into an Azure SQL DB staging table. The
foreachBatch()method sets the output of the streaming query to be processed using the provided function.
<br>
# Output Dataframe to JSON files<br>
df_out = df_transform.writeStream\<br>
.trigger(once=True)\<br>
.format("json")\<br>
.outputMode("append")\<br>
.option("checkpointLocation", "abfss://checkpointcontainer@dstore.dfs.core.windows.net/checkpointcsv")\<br>
.start("abfss://rawcontainer@dstore.dfs.core.windows.net/autoloaderjson")</p>
<p># Output Dataframe to Azure SQL DB<br>
df_sqldb = df_transform.writeStream\<br>
.trigger(once=True)\<br>
.foreachBatch(output_sqldb)\<br>
.outputMode("append")\<br>
.option("checkpointLocation", "abfss://checkpointcontainer@dstore.dfs.core.windows.net/checkpointdb")\<br>
.start()<br>
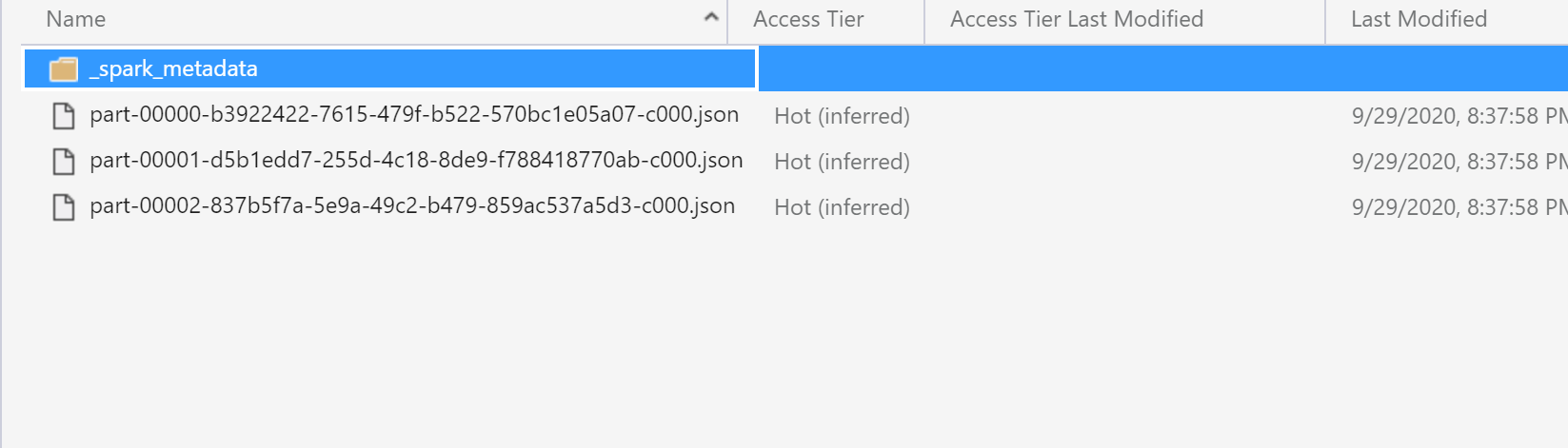
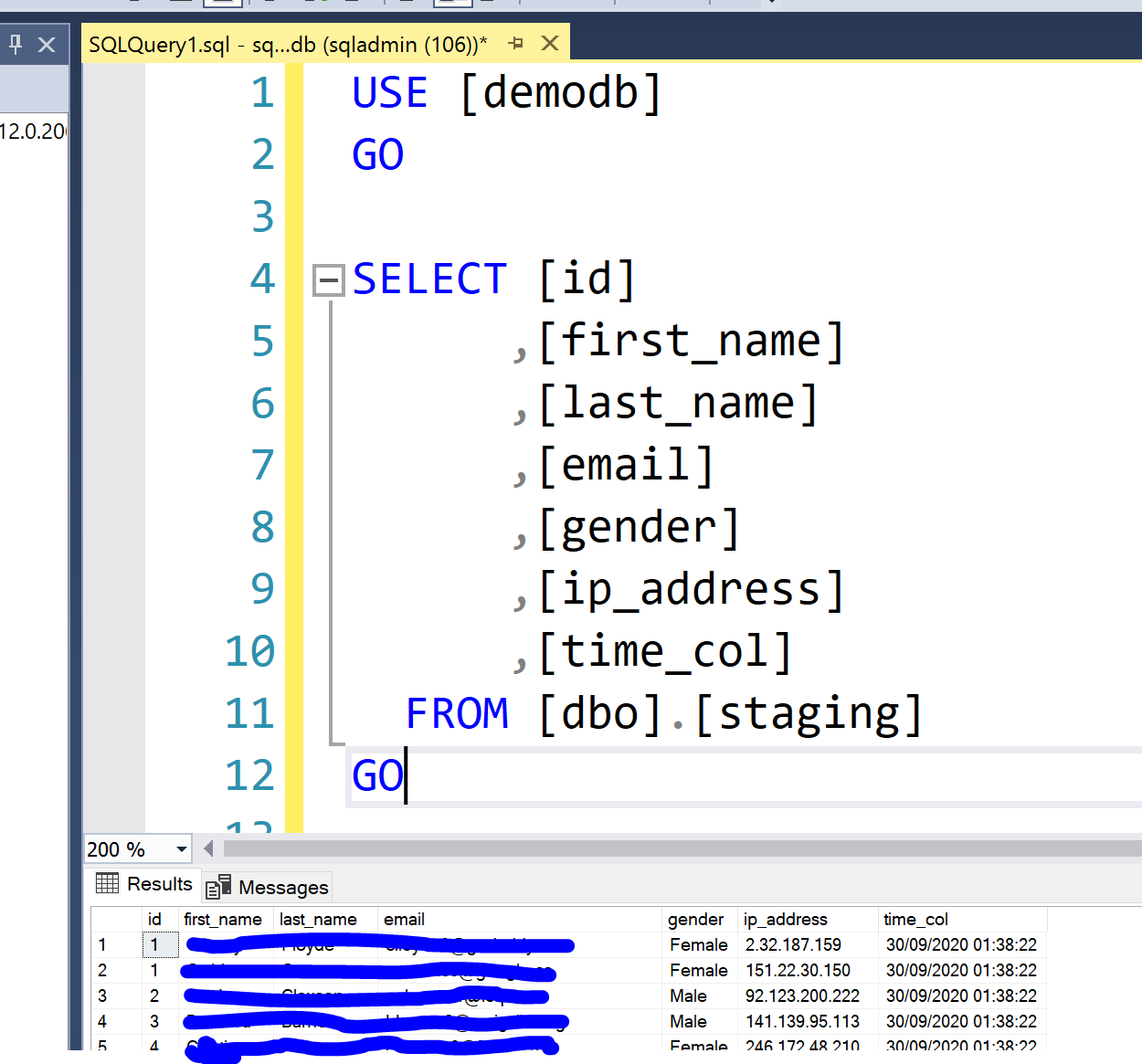
The following screenshots show the successful write of the csv files as JSON and into the Azure SQL DB table:
Output JSON File Sink:
Output Staging Table:
Key Points.
1. A critical point of note in this pipeline configuration for my use case is the Trigger once configuration. The trigger once option enables running the streaming query once, then it stops. This means that I can schedule a job that runs the notebook however often is required, as a batch job. The cost savings for this option are huge.
I don’t have to leave a cluster running 24/7 just to perform a short amount of processing hourly or once a day. This is the best of both worlds. I code my pipeline as a streaming ETL, while running it as a batch process to save cost. And there’s no data copy operation involved that will very much add a lot more latency to the pipeline.
2. The checkpoint option in the writeStream query is also exciting. This checkpoint location preserves all of the essential information that uniquely identifies a query. Hence, each query must have a different checkpoint location, and multiple queries should never have the same location. It is a part of the fault tolerance functionality built into the pipeline.
Big data processing applications have grown complex enough that the line between real-time processing and batch processing has blurred significantly. The ability to use the Streaming API to simplify batch-like ETL pipeline workflows is awesome and a welcome development.
The full notebook source code can be found here.
