Databricks is a distributed data analytics and processing platform designed to run in the Cloud. This platform is built on Apache Spark which is currently at version 2.4.4.
In this post, I will demonstrate the deployment and installation of custom R based machine learning packages into Azure Databricks Clusters using Cluster Init Scripts. So, what is a Cluster Init Script ?
Cluster Initialization Scripts:
These are shell scripts that are run and processed during startup for each Databricks cluster node before the Spark driver or worker JVM starts. Some of the tasks performed by init scripts include:
1) Automate the installation of custom packages and libraries not included in the Databricks runtime. This can also include the installation of custom-built packages that are not available in public package repositories.
2) Automate the setting system properties and environment variables used by the JVM.
3) Modify Spark configuration parameters.
4) Modify the JVM system classpath in special cases.
Note: The Databricks CLI can also be used to install libraries/packages so long as the package file format is supported by Databricks. To install Python packages, use the Databricks pip binary located at /databricks/python/bin/pip (this path is subject to change) to ensure that Python packages install into the Databricks Python virtual environment rather than the system Python environment. For example, /databricks/python/bin/pip install.
Cluster Init Script Types:
There are two types of cluster scripts currently supported by Databricks:
1) Cluster-scoped scripts
2) Global Init scripts.
For this blog post, I will be focusing on Cluster-scoped init scripts. I will note that Global init scripts are developed to run on every cluster in a workspace.
Databricks clusters are provisioned with a specific set of libraries and packages included. For the custom R packages to be installed and available on the cluster nodes, they have to be compressed using the tar.gzip file format as a requirement. At the time of this writing, this file format is not supported for installing packages to a Databricks cluster as confirmed using the Databricks CLI libraries install subcommand:

Based on the above screen shot, we can see that for now, the supported package formats using the Databricks CLI are:
jar,
egg,
whl,
maven-coordinates,
pypi-package,
cran-package
Creating and Deploying an example Cluster Init Script:
This sample Cluster-init script was developed on a Windows 10 machine using the Visual Studio Code editor. Before the custom package can be executed and installed on the Cluster nodes, it will have to be deployed to the Databricks File System in the Databricks workspace, together with the cluster-init script file. To deploy the script to the Databricks File System (DBFS) for execution, I’ll use the Databricks CLI tool (which is a REST API wrapper). The following shell script sample first installs a public package xgboost from the Cran repository using the install.packages() R function, then implements a “for loop” to install the packages defined in the list. The install.packages() R function script is run from the cluster nodes’ ubuntu R interactive shell:
#!/bin/bash
sudo R --vanilla -e 'install.packages("forecast", repos="http://cran.us.r-project.org")'
MY_R_PACKAGES="ensembleR.tar.gzip"
for i in $MY_R_PACKAGES
do
sudo R CMD INSTALL --no-lock /dbfs/custom_libraries/$i
done
The following one line databricks cli scripts create the dbfs directory location for the cluster-init script and custom packages path:
databricks.exe --profile labprofile fs mkdirs dbfs:/custom_libraries
databricks.exe --profile labprofile fs mkdirs dbfs:/custom_libraries
databricks.exe fs mkdirs dbfs:/databricks/packages_libraries
databricks.exe --profile labprofile fs cp .\my_cluster_init.sh dbfs:/custom_libraries
databricks.exe --profile labprofile fs cp .\ensembleR.tar.gzip dbfs:/databricks/packages_libraries/
Accessing and Viewing Cluster Init Script Logs:
In the event of an exception in the Cluster-init script execution, the Cluster creation operation fails and the Databricks workspace UI event log does not reveal much as to the cause of the failure.
The cluster init script logs located at dbfs:/databricks/init_scripts can be downloaded via the Databricks CLI as part of the debugging process.
Define the Cluster-scoped Init script in a Cluster creation API request:
{
"cluster_name": "Demo-Cluster",
"spark_version": "5.0.x-ml-scala2.11",
"node_type_id": "Standard_D3_v2",
"cluster_log_conf": {
"dbfs" : {
"destination": "dbfs:/cluster-logs"
}
},
"init_scripts": [ {
"dbfs": {
"destination": "dbfs:/custom_libraries/my_cluster_init.sh"
}
} ],
"spark_conf":{
"spark.databricks.cluster.profile":"serverless",
"spark.databricks.repl.allowedLanguages":"sql,python,r"
},
"custom_tags":{
"ResourceClass":"Serverless"
},
"autoscale":{
"min_workers":2,
"max_workers":3
}
}
Databricks Workspace GUI Reference of the Cluster Init Script Location:
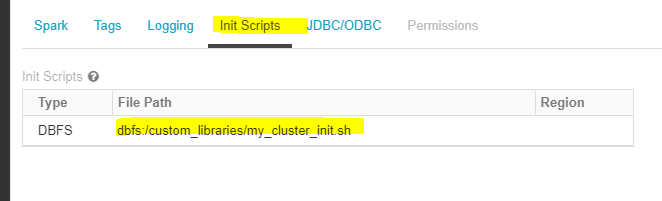
Confirm Installed Custom Packages:
To confirm successful installation of the R package, create a new Databricks notebook, attach the notebook to the newly created cluster and run the following R script:
%r ip <- as.data.frame(installed.packages()[,c(1,3:4)]) rownames(ip) <- NULL ip <- ip[is.na(ip$Priority),1:2,drop=FALSE] print(ip, row.names=FALSE)
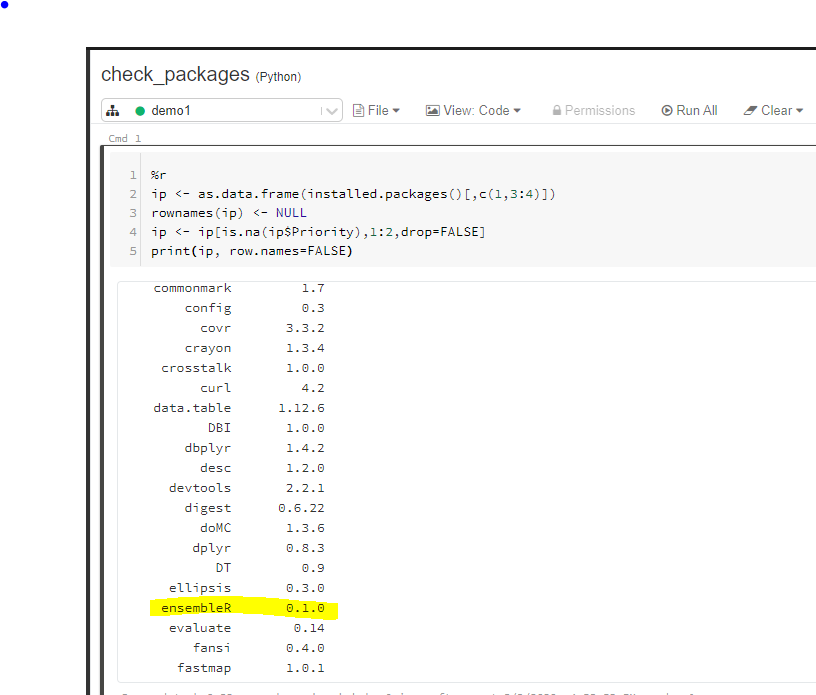
Based on the screen shot above, the package was successfully deployed via the cluster init script. In a future post, I will explore techniques for debugging a failed Cluster Init script deployment and steps for resolving any exceptions during the cluster creation process.
